
Distillation Enabling Big Uptake of Small Models
Google's latest announcement showcases industry trend towards smaller model adoption

Leaps in Small Model Adoption
In the last year, adoption has surged for small models. In general, scaling laws predict that the larger the model, the greater the intelligence. But more and more, smaller models are punching above their weight.
Recent small model releases from the large research labs have outperformed on many benchmark intelligence tests (and are cheaper and faster to boot). Google’s latest major product announcement is a good example where the smaller Gemini 2.0 Flash experimental model outperformed the larger Gemini 1.5 Pro model on seven out of nine test categories. Anthropic provides another example, where its mid-range Sonnet 3.5 model is currently outperforming its larger, current flagship Opus 3 model (a next gen, Opus 3.5 model has yet to be released).
What’s behind this phenomenon?
Key Enablers: Synthetic Data and Model Distillation
Improvements in model training, involving synthetic data and model distillation are key drivers for more capable, smaller models.
Andrej Karpathy noted that current training methods rely heavily on “memorizing the internet.” In other words, today’s models ingest vast amounts of raw data that blend “knowledge” with “thinking.” “Knowledge” includes facts, figures, but often useless or repetitive details (like SHA hashes of common numbers, or “hello world” examples in computer science). Embedded within this knowledge is “thinking”: the reasoning processes and frameworks that allow models to approach problems and produce intelligent answers. It’s this “thinking” that genuinely matters for building more effective models.
Model distillation offers a path forward. Large, inefficiently trained models can generate more refined, synthetic training sets that contain a higher ratio of “thinking” to “knowledge.” Smaller models are then trained on this distilled data, enabling them to become just as effective as the original large models—without having to memorize the entire internet.
This process can repeat over multiple iterations, with each new generation of models refining the training data further. Ultimately, smaller models will emerge that “think” just as well as today’s state-of-the-art systems. They may not recall every obscure chemistry fact, but they will be far more efficient and practical.
Visualizing Price / Quality Trade-Offs
This trend can be observed using some of the open benchmarking tools currently published (a good one is artificial intelligence.ai, reproduced below and linked here):
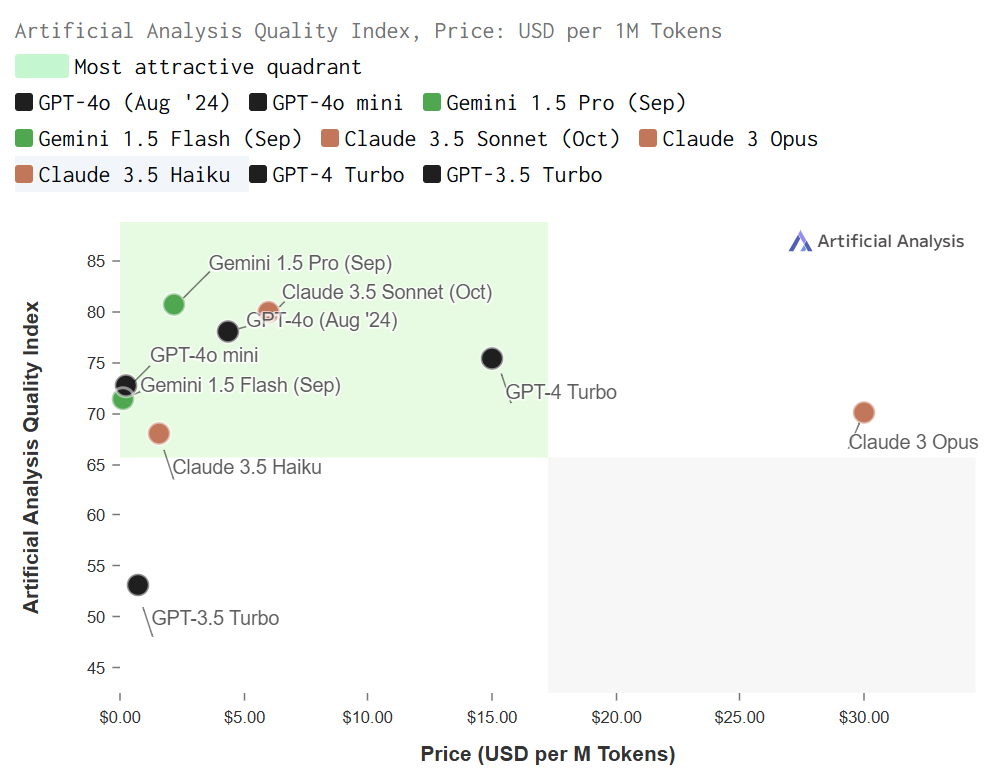
Some of the large research labs have actively disclosed their use of model distillation like Google for its Gemini models (whitepaper link here), informing the comparison between Gemini 1.5 Pro used to train Gemini 1.5 Flash. For others, like Claude 3 Opus training Claude 3.5 Haiku or GPT 4o training GPT 4o-mini, the comparisons are based on commentary in the community. Lastly as a point of comparison, the above includes models from a year previous (GPT 4-Turbo and GPT 3.5 Turbo).
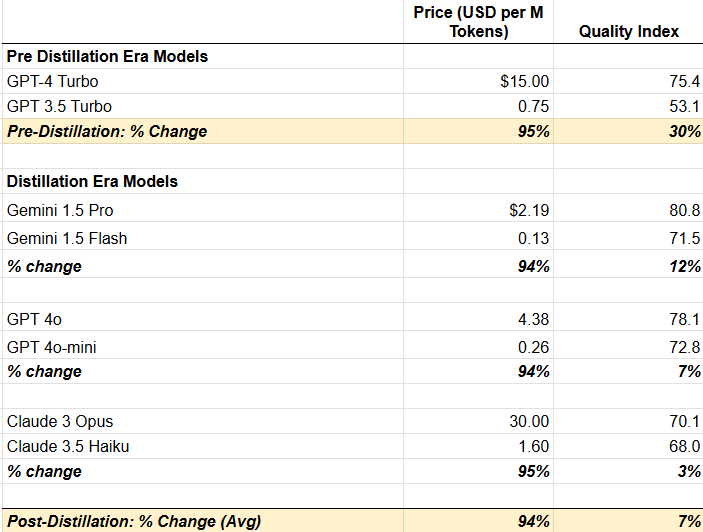
Summarizing some of the changes, pre-distillation you could expect a 95% reduction in price drove a 30% reduction in intelligence / quality. Today, similar reductions in price are driving on average just a 7% reduction in intelligence / quality. For this and many other reasons, more and more production use cases are taking advantage of smaller models given the attractive price per intelligence characteristics.